Programmer Whisper
This website records my snippets, patterns, and some practices.
行動裝置上的悉曇文字處理
- 19 Dec 2024
- unicode
1. 字型支援:
- iOS : 內建,可直接使用 system
- Android : 需載入字型檔。已知有以下選擇: Noto Sans Siddham, ApDevaSiddham, 以及 Muktamsiddham
2. 文字渲染結果:
悉曇文字在呈現時,會有將母音與子音相組合,以及子音彼此之間相組合等各種情況(孤合字,滿字,種子字…)。
下表為各字型在渲染結果上的差異:
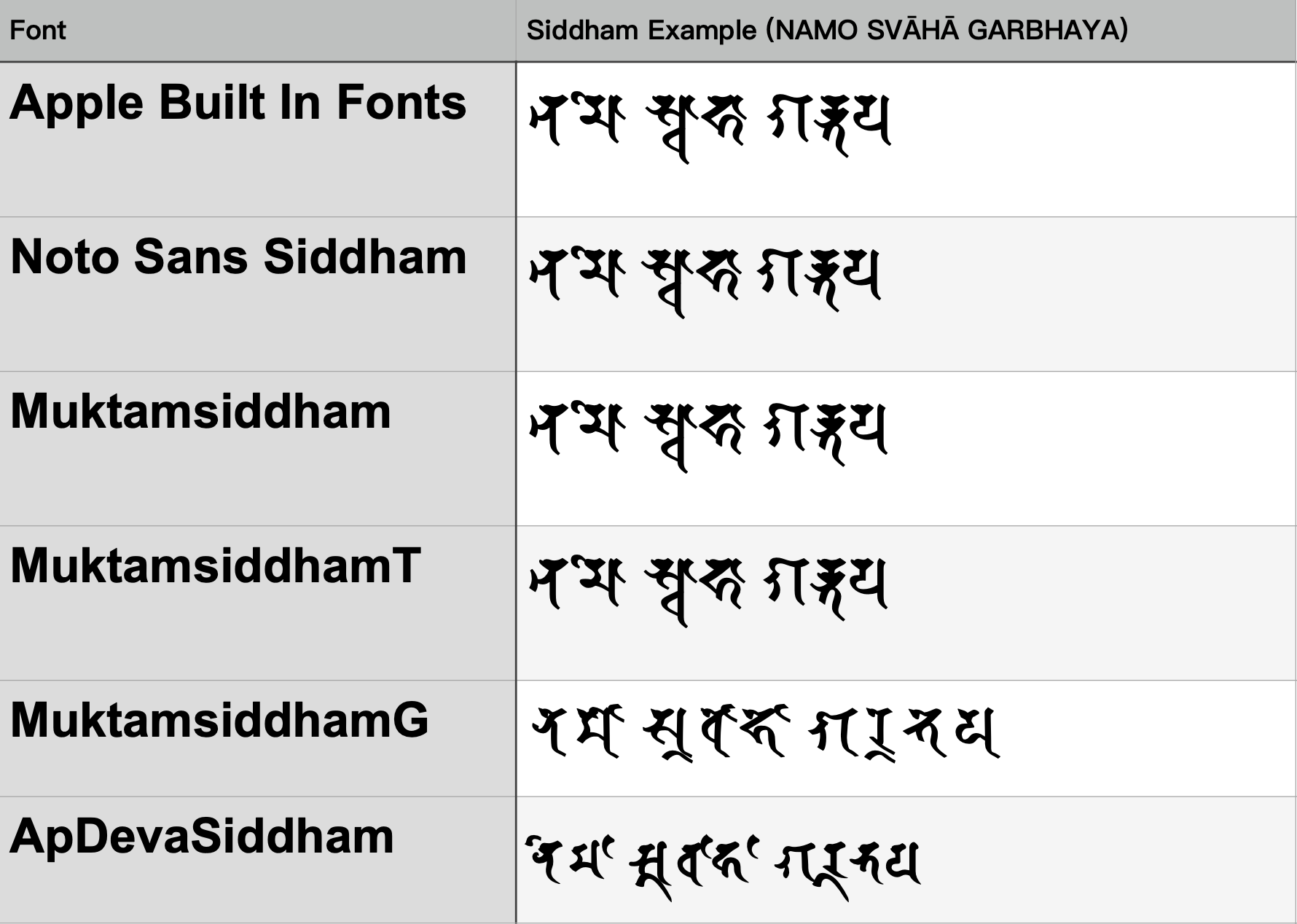
從渲染結果來看,iOS 可直接使用系統內建字型。而 Android 則建議使用Noto Sans Siddham字型。
3. 拆分字組:
拆分句子為單獨字元時,則不論是iOS或Android,在孤合字,滿字的判斷上,都出現預期外的結果。
例如: 𑖭𑖿𑖪𑖯𑖮𑖯(svāhā, 娑婆訶) 為佛教真言中常見結尾。
在 iOS 中,用 String.flatMap 拆解 𑖭𑖿𑖪𑖯𑖮𑖯,會得到: 𑖭𑖿、𑖪𑖯、𑖮𑖯 而非 𑖭𑖿𑖪𑖯、𑖮𑖯。
在Android 系統中,使用 BreakIterator 結果亦同。
考慮到不論iOS/Android底層文字處理,都是透過 icu 函式庫,且拆分結果與字型無關,有必要深入瞭解原因與解法。
4. 梵字組成方式,以及可能的問題原因:
印度語系中,有所謂半聲,半字,又稱毗藍摩(Virama)的概念。字母表中的子音,是用一個子音 + a 組成,稱為體文,如 (𑖎, ka)。實際上需要標示單一子音時,會加上 𑖿 (毗藍摩)表示將母音的部分移除。 例如:
(𑖎𑖿 , k) = (𑖎, ka) + (𑖿, Virama)
此時,單一子音,會被稱為半字,或是孤合字(單獨使用時)。當半字再加上不同母音修飾符時,才會組成一個滿字。
(𑖎𑖲 , ku) = (𑖎, ka) + (𑖲 ,Vowel Sign U)
另外,多個子母音之間,也可以透過毗藍摩組成更複雜的字,上面範例中所用的 𑖭𑖿𑖪𑖯𑖮𑖯 即是。
(𑖭𑖿𑖪𑖯𑖮𑖯, svāhā) = (𑖭, sa) + (𑖿, Virama) + (𑖪, va) + (◌𑖯, Vowel sign Ā) + (𑖮, ha) + (◌𑖯, Vowel sign Ā)
從上面的結構,以及目前iOS/Android拆解字組的結果可知,目前icu的演算法,在拆字時,會直接將 𑖿 (Virama) 視做字組的結尾,而不是兩個半字的連接符。這是因為icu在處理悉曇文的拆解時,直接套用預設字素規則所導致的,特別是GB9規則。然而,在印度語系中,毗藍摩(Virama)取代了Zero Width Joiner(ZWJ)的功能,直接套用GB9規則,會造成拆字時,將毗藍摩(Virama)視為每一個字的結尾。
在渲染時則無此問題,單純依照字體是否支援,來決定如何渲染字型(參照 N4294,section 3.9,Default Representation 一節)。
5. 可能的處理方式:
-
暴力解:對於較短的字句,可以直接依照需要拆解,例如六字真言: 𑖌𑖼𑖦𑖜𑖰𑖢𑖟𑖿𑖦𑖸𑖮𑖳𑖽
透過icu的拆解結果會是: 𑖌𑖼 𑖦 𑖜𑖰 𑖢 𑖟𑖿 𑖦𑖸 𑖮𑖳𑖽
手動拆解則可以自行分配字組: 𑖌𑖼 𑖦 𑖜𑖰 𑖢 𑖟𑖿𑖦𑖸 𑖮𑖳𑖽
這種做法的好處在於直觀,但缺點在於無法複用,套用在長文時也很花時間。
-
引入並擴充 icu 函式庫,對印度語系中的virama 做特殊處理。目前icu對天城文的字素已有做擴充處理,應該可以直接套用,這也是正規的解法。
缺點在於引入函式庫會造成程式的擴張,也會需要理解架構以及改寫的時間。另外也不確定是否會與iOS/Android內建的功能造成衝突。
-
針對悉曇文的拆解,不依賴icu,而是自行對unicode進行拆解,依照悉曇文組字規則,反向寫出拆字規則。
優點:規則可以自行掌握,增減,可以快速實作,不需依賴其他函式庫。也可以用在較長的文本上。 缺點:測試資料,文本不足,無法保證涵蓋所有狀況。
6. 實作:
依照目前的需求,因為匯入文本可以事先做處理,減少一些需要判斷的狀況(例如開頭,標點,裝飾文字等…),採用解法 3 在開發速度以及程式複雜度上,會是比較適合的選擇。
實際做法,考量到多平台相容性,用正規表示式來匹配字元會是比較好的做法:
/([\x{1158E}-\x{115AE}](?:(\u{115BF}[\x{1158E}-\x{115AE}][\x{115AF}-\x{115BB}]?)+|[\x{115AF}-\x{115BB}])?)|([\x{11580}-\x{1158D}]([\x{115BC}\x{115BD}]\x{115BE}?|\x{115BE})?)/
正規表示式內容說明:
- Regex的Unicode語法: \X{DDDDD} 在Regex中,用16進位表示unicode的code point.
- 在較新的規範中,\U{} 特指unicode的 code point,而\X{} 則指涉所有 16 進位數字。在考慮平台相容性的情況下,使用\X{} 來標記所有 unicode的 code point.
- [\x{AAAAA}-\x{BBBBB}] 表示匹配任何範圍在 AAAAA-BBBBB的 code point
- 注意,對一些較舊的Regex Engine,並不支援\x{}擴展到5個位元。在此情況下,有必要將碼點從U+AAAAA轉換為U+BBBBU+CCCC組合的形式。轉換的方式則請參考Unicode標準,或是利用線上工具幫忙轉換。
- 實際內容說明:
-
上述表示式,粗略拆分為前後兩部分:
第一部分:
([\x{1158E}-\x{115AE}](?:(\u{115BF}[\x{1158E}-\x{115AE}][\x{115AF}-\x{115BB}]?)+|[\x{115AF}-\x{115BB}])?)- [\x{1158E}-\x{115AE}] : 抓取範圍在U+1158E 到 U+115AE的字元,此範圍即為悉曇文的體文部分。
- \u{115BF}為virama字符。
- [\x{115AF}-\x{115BB}] 為母音符號,用來與半字合成滿字
- 第一段的結構可重寫為 «子音»((«毗藍摩»«子音»«母音符號»)+|«母音符號»,意即抓出所有滿字,包括多個半字相聯結,以及半字直接加上母音的狀況。也就是所有包含子音的字元。
第二部分:
([\x{11580}-\x{1158D}]([\x{115BC}\x{115BD}]\x{115BE}?|\x{115BE})?)此段用以抓取以所有的字母開頭(子音+母音),後面接上仰月點或明點,以及止韻的情況。這是用來補足抓取單一母音,以及字母有加上特殊符號的情況。
-
程式碼:
extension String { var isSiddham: Bool { contains(/[\u{11580}-\u{115C9}]/) } func splitSiddhamChars() -> [String] { guard isSiddham else { return [] } return matches(of: /([\u{1158E}-\u{115AE}](?:(\u{115BF}[\u{1158E}-\u{115AE}][\u{115AF}-\u{115BB}]?)+|[\u{115AF}-\u{115BB}])?)|([\u{11580}-\u{1158D}]([\u{115BC}\u{115BD}]\u{115BE}?|\u{115BE})?)/.matchingSemantics(.unicodeScalar)).reduce([]) { partialResult, match in partialResult + [String(self[match.range])] } } }
val pattern = "([\\x{1158E}-\\x{115AE}](?:(\\x{115BF}[\\x{1158E}-\\x{115AE}][\\x{115AF}-\\x{115BB}]?)+|[\\x{115AF}-\\x{115BB}])?)|([\\x{11580}-\\x{1158D}]([\\x{115BC}\\x{115BD}]\\x{115BE}?|\\x{115BE})?)" val regex = Regex(pattern) regex.findAll("test string").map { // process each grapheme } -
- 測試例:
- 使用虛空藏菩薩求聞持法做為測資:𑖡𑖦𑖺𑖁𑖎𑖯𑖫𑖐𑖨𑖿𑖥𑖧𑖌𑖼𑖁𑖨𑖿𑖧𑖎𑖦𑖨𑖰𑖦𑖻𑖩𑖰𑖭𑖿𑖪𑖯𑖮𑖯
- 可完整取出18個字元。
- 後續改進方向: 目前的改善方案,只依據有遇到的狀況做處理,若有其他情況,則需另外再填加條件。
–
附錄:悉曇文在Unicode 渲染規則的簡易整理
參考文件:
- 萬國碼標準文件:
- 梵文研究古籍:(公開領域資料,可在 Wikimedia Commons 搜尋)
- 悉曇字記
- 悉曇三密鈔
- 佛學名詞資料:參照佛光大辭典
- 區塊範圍: U+11580 - U+115FF, 實際使用 U+11580 - U+115DD
- 子類別:
- 獨立母音 U+11580 - U+1158D, 又稱摩多,雲韻
- 子音 U+1158E - U+115AE, 又名體文
- 母音符號 U+115AF - U+115BB, 用來跟子音合成滿字, ex : 體文 (𑖎, ka),要變為 k + ā 發長音時 (𑖎, ka) + (◌𑖯, ā) -> (𑖎𑖯, kā)。 或要變為 ku 時, (𑖎, ka) + (◌𑖲 , u) -> (𑖎𑖲, ku)
- 母音修飾符 U+115BC-U+115BD(仰月點, Candrabindu - 明點, Anusvara), U+115BE (止韻, Visarga)
- 毗藍摩,怛達點畫 U+115BF 用來將體文變做半體,與其他子音,相結合成為滿字,依聲韻學的角度來看,體文型式為子音加母音A,透過毗藍摩組合,表示將母音去除,單發子音。 ex: 體文 (𑖎, ka) + (◌𑖿 , virama) -> 子音 (𑖎𑖿 , k), 此時為孤合字,可獨立使用,多發生於詞尾。 如果後面再接另一體文 (𑖎𑖿 , k) + 體文 (𑖪 , va) -> 滿字 (𑖎𑖿𑖪, kva, 迦嚩)
- 變音修飾符 U+115C0, 用在現代悉曇文中,用以標示原本悉曇文中不存在的發音, ex: (𑖎, ka) -> (𑖎𑗀, qa)
- 開頭標記, (𑗁, Siddham) U+115C1,用於文章開頭
- 標點 U+115C2 (𑗂, Daṇḍa, 但荼),用於句尾。 U+115C3 (𑗃, Double Daṇḍa, 但荼),用於段落結束。 U+115C4 (𑗄, Separator-1) 分隔符1,用於分隔字母與詞組 U+115C5 (𑗅, Separator-2) 分隔符2,用於分隔字母與詞組
- 終端標記, (𑗉, End of Text) 用於全文結束時。